
- 软件介绍
- 软件信息
- 相关下载

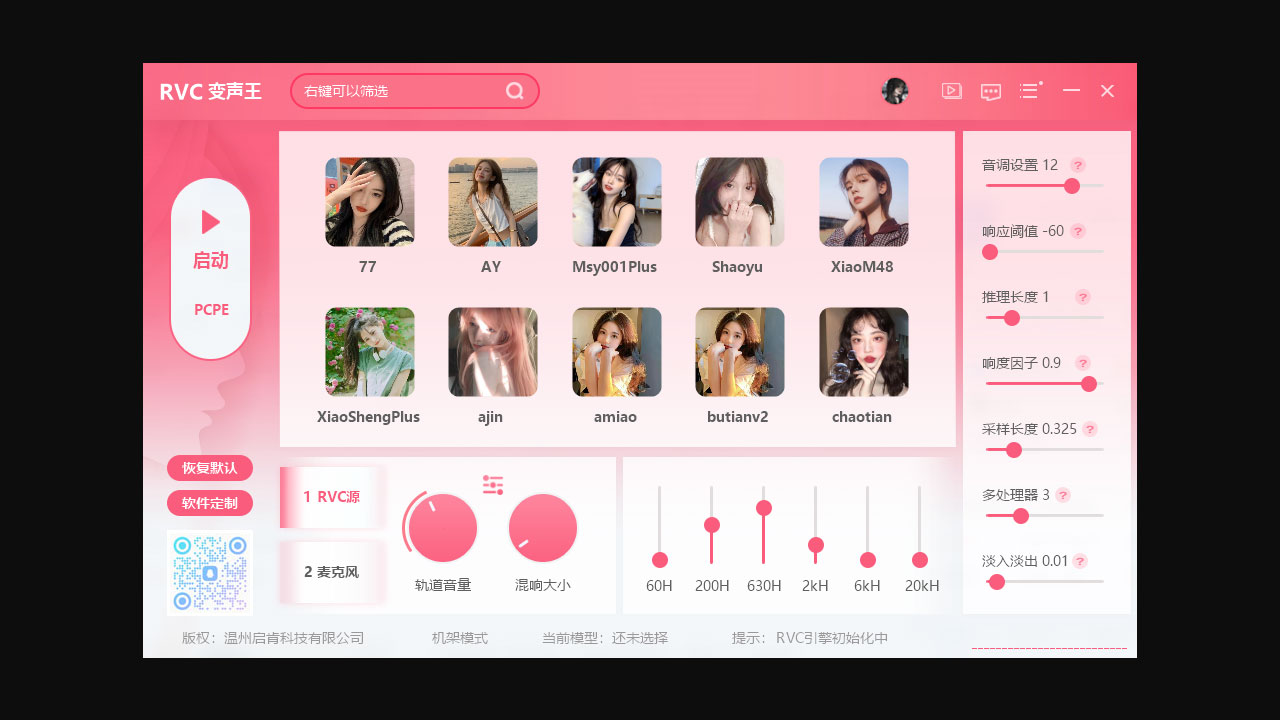

RVC变声器模型是一款基于深度学习的AI变声软件,由专业音频团队开发,广泛应用于虚拟主播、游戏配音、音乐创作等领域,该模型通过先进的声学特征提取和转换算法,能够实现高质量的声音转换,支持多种音色风格,包括男声、女声、童声及各种角色化声音效果。
rvc变声器模型亮点
1、高保真音色转换
采用VITS语音合成系统作为基础框架,结合深度学习技术,确保转换后的声音自然流畅,避免机械感或失真问题。
2、低资源消耗
相比传统AI变声模型,RVC在保证音质的同时优化了计算效率,即使在中低端显卡上也能流畅运行,大幅降低硬件门槛。
3、灵活模型训练
支持用户使用少量语音数据自行训练个性化音色模型,适用于虚拟主播、游戏角色配音等场景,满足定制化需求。
4、多平台兼容
兼容NVIDIA、AMD和Intel核显等多种硬件配置,并提供Windows/Linux系统支持,适配不同用户的设备环境。
5、实时变声能力
结合实时音频处理技术,可在直播、录音等场景中即时应用变声效果,延迟低至几十毫秒,适合互动性强的应用场景。
RVC变声器模型功能
1、多风格音色转换
提供多种预设音色模板,用户也可导入自定义模型实现更丰富的声音效果。
2、精细参数调节
支持调整音调、共振峰、语速等核心参数,实现从轻微变声到完全角色化声音的平滑过渡。
3、降噪与增强
内置AI降噪模块,可自动消除录音中的环境噪音,同时保留人声细节,提升最终音质。
4、模型融合功能
允许用户混合多个训练好的模型,创造出独特的复合音色,如"少年+电子音效"等创新组合。
5、UVR5人声分离支持
可调用UVR5模型快速分离人声和伴奏,便于提取纯净人声进行变声处理,提高工作效率。
6、实时监听与预览
在训练和变声过程中提供实时音频反馈,用户可通过耳机即时听到效果并进行微调。
安装指南
1、在本站下载rvc变声器模型安装包。
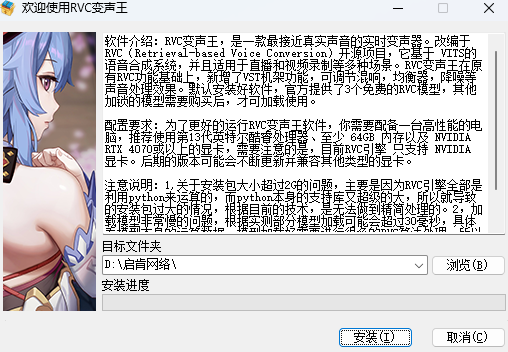
2、双击安装文件,按照提示逐步完成安装,可选择默认路径或自定义存储位置。
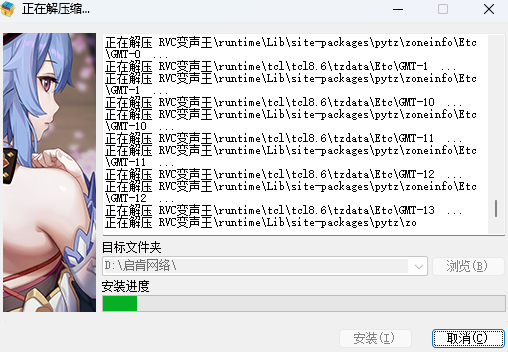
3、安装完成后打开软件,即可开始使用软件。
常见问题解答
Q:RVC变声器模型需要什么硬件配置?
A:基础变声功能可在CPU上运行,但实时处理推荐使用NVIDIA显卡,训练模型建议至少4GB显存,低显存用户可通过减小batch_size来适配。
Q:如何获取高质量的训练数据?
A:建议录制10-30分钟的单人稳定发音音频,环境噪音越小越好,可使用UVR5模型辅助分离人声,或通过降噪软件预处理原始录音。
Q:训练好的模型可以分享给他人使用吗?
A:可以,只需将Pth和Index模型文件打包发送,他人加载后即可使用相同的音色效果,注意保护隐私,避免使用含敏感内容的音频训练。
Q:为什么变声后声音会有机械感?
A:可能原因包括:
1、训练数据不足,建议增加录音时长;
2、参数设置不当,尝试调整Pitch或Formant值;
3、模型未充分训练,增加epoch数量。
Q:支持哪些音频格式输入/输出?
A:实时变声支持麦克风直接采集,训练环节可处理WAV/MP3等常见格式,最终输出质量取决于输入源和模型精度。
- 软件厂商:温州启肯电子科技有限公司
- 备案号:浙ICP备19035514号-15
- 软件分类: 音频处理
- 运行环境: win7及以上
- 官网地址:http://www.rvcbs.com/
- 软件语言: 简体中文
- 授权: 免费软件
- 软件类型: 多媒体软件









 客户端
客户端 回顶部
回顶部